1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
|
import aiohttp
import asyncio
import urllib
import aiofiles
import asynqp
import os
base_save_path = "f"
mq_host = "192.168.199.13"
mq_user = "admin"
mq_password = "123123"
bucket = "bucket_name"
hostname = "http://xxxxxx"
username = "username"
password = "password"
auth = base64.b64encode(f"{username}:{password}".encode(encoding="utf-8"))
headers = {}
headers["Authorization"] = "Basic " + str(auth)
headers["User-Agent"] = "UPYUN_DOWNLOAD_SCRIPT"
headers["x-list-limit"] = "300"
class Spider:
def __init__(self, max_task=10, max_tried=4):
print(f"新建spider! 线程数:{max_task} 每次最多重试次数: {max_tried}")
self.loop = asyncio.get_event_loop()
self.max_tries = max_tried
self.max_task = max_task
self.session = aiohttp.ClientSession(loop=self.loop)
def close(self):
"""回收http session"""
self.session.close()
async def download_work(self):
try:
while True:
received_message = await self.queue.get()
if received_message is None:
await asyncio.sleep(1)
continue
msg_json = received_message.json()
await self.handle(msg_json)
received_message.ack()
await asyncio.sleep(500) #爬太快了消费不了 加了很久的延迟
except asyncio.CancelledError:
pass
async def handle(self, key):
"""处理接口请求"""
url = "/" + key["bucket"] + \
(lambda x: x[0] == "/" and x or "/" + x)(key["key"])
url = url.encode("utf-8")
url = urllib.parse.quote(url)
if key["x-list-iter"] is not None:
if key["x-list-iter"] is not None or not "g2gCZAAEbmV4dGQAA2VvZg":
headers["X-List-Iter"] = key["x-list-iter"]
tries = 0
while tries < self.max_tries:
try:
reque_url = "http://v0.api.upyun.com" + url
print(f"请求接口:{reque_url}")
async with self.session.get(reque_url, headers=headers, timeout=60) as response:
content = await response.text()
try:
iter_header = response.headers.get("x-upyun-list-iter")
except:
iter_header = "g2gCZAAEbmV4dGQAA2VvZg"
list_json_param = content + "`" + \
str(response.status) + "`" + str(iter_header)
await self.do_file(self.get_list(list_json_param), key["key"], key["hostname"], key["bucket"])
break
except aiohttp.ClientError:
pass
tries += 1
def get_list(self, content):
# print(content)
if content:
content = content.split("`")
items = content[0].split("\n")
content = [dict(zip(["name", "type", "size", "time"], x.split("\t"))) for x in items] + content[1].split() + \
content[2].split()
return content
else:
return None
async def do_file(self, list_json, key, hostname, bucket):
"""处理接口数据"""
for i in list_json[:-2]:
if not i["name"]:
continue
new_key = key + i["name"] if key == "/" else key + "/" + i["name"]
try:
if i["type"] == "F":
await self.put_key_queue({"key": new_key, "x-list-iter": None, "hostname": hostname, "bucket": bucket})
# self.key_queue.put_nowait(
# {"key": new_key, "x-list-iter": None, "hostname": hostname, "bucket": bucket})
else:
save_path = "/" + bucket + new_key
if not os.path.isfile(base_save_path + save_path):
await self.put_pic_queue({"key": new_key, "save_path": save_path, "x-list-iter": None, "hostname": hostname, "bucket": bucket})
#else:
# print(f"文件已存在:{base_save_path}{save_path}")
except Exception as e:
print("下载文件错误!:" + str(e))
async with aiofiles.open("download_err.txt", "a") as f:
await f.write(new_key + "\n")
if list_json[-1] != "g2gCZAAEbmV4dGQAA2VvZg":
# self.key_queue.put_nowait(
# {"key": key, "x-list-iter": list_json[-1], "hostname": hostname, "bucket": bucket})
await self.put_key_queue({"key": key, "x-list-iter": list_json[-1], "hostname": hostname, "bucket": bucket})
async def put_key_queue(self, obj):
msg = asynqp.Message(obj)
self.exchange.publish(msg, f"{bucket}.routing.key.key")
async def put_pic_queue(self, obj):
msg = asynqp.Message(obj)
self.pic_exchange.publish(msg, "routing.pic.key")
async def run(self):
self.connection = await asynqp.connect(host=mq_host, username=mq_user, password=mq_password)
self.channel = await self.connection.open_channel()
self.exchange = await self.channel.declare_exchange("key.exchange", "direct")
self.queue = await self.channel.declare_queue(f"{bucket}.key.queue", durable=True)
await self.queue.bind(self.exchange, f"{bucket}.routing.key.key")
self.channel_pic = await self.connection.open_channel()
self.pic_exchange = await self.channel_pic.declare_exchange("pic.exchange", "direct")
self.pic_queue = await self.channel_pic.declare_queue("pic.queue", durable=True)
await self.pic_queue.bind(self.pic_exchange, "routing.pic.key")
# 这里新的空间才需要爬取根目录
# await self.put_key_queue({"key": "/", "x-list-iter": None,"hostname": hostname, "bucket": bucket})
for _ in range(self.max_task):
asyncio.ensure_future(self.download_work())
await asyncio.sleep(2.0)
if __name__ == "__main__":
loop = asyncio.get_event_loop()
spider = Spider(max_task=10)
# asyncio.ensure_future(spider.run())
loop.run_until_complete(spider.run())
loop.run_forever()
# print(f"Pending tasks at exit:{asyncio.Task.all_tasks(loop)}")
spider.close()
loop.close()
|
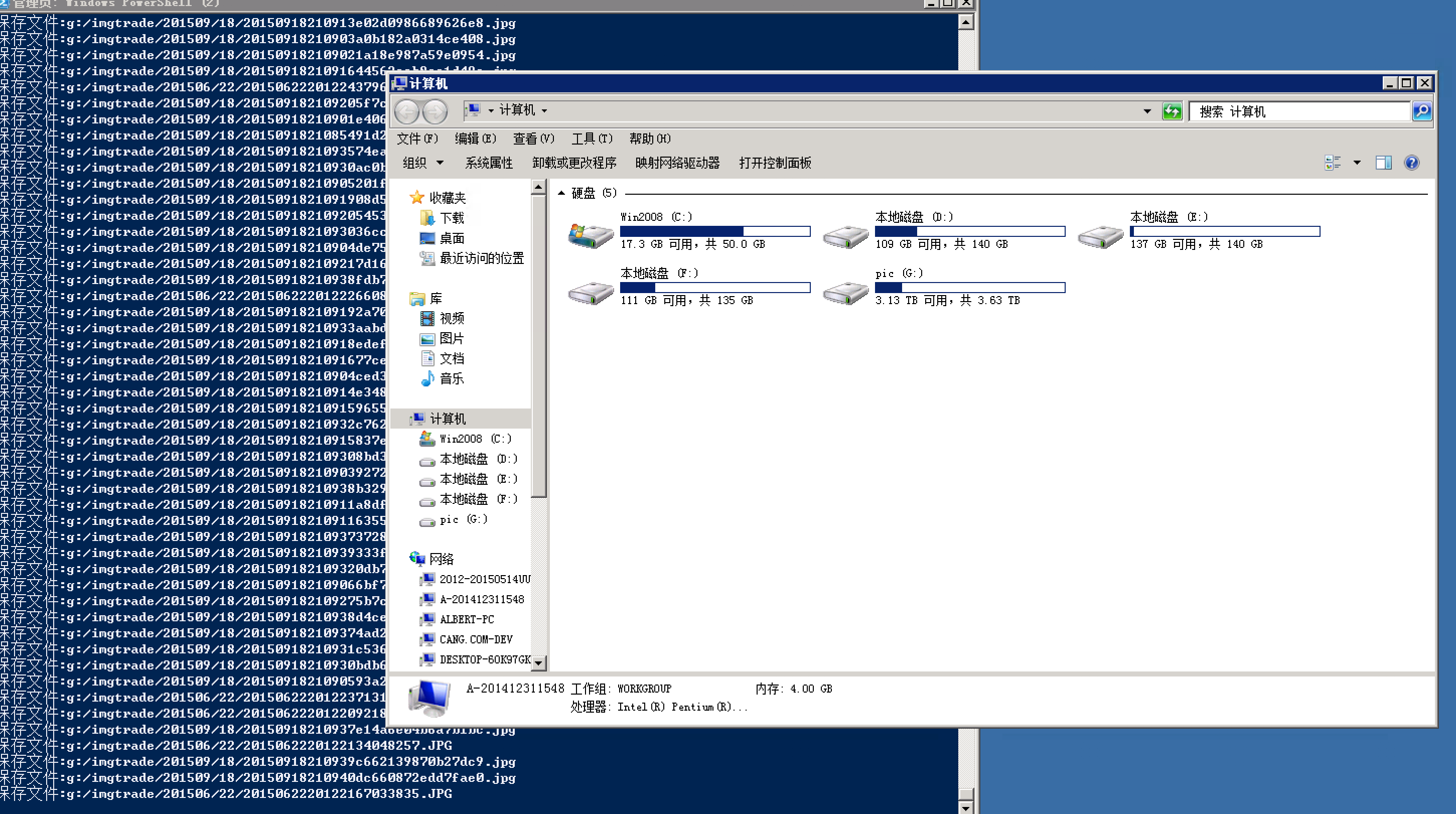 ◎ WX20170906-144202
◎ WX20170906-144202 ◎ WX20170906-144225@2x
◎ WX20170906-144225@2x ◎ WX20170906-144238@2x
◎ WX20170906-144238@2x