2.汇编-内存
寄存器数量和容量有限,为了存储大量数据,所以我们需要内存
- 每个程序都会有自己的独立的4GB内存空间(
这里的内存其实是虚拟的,并不是真的给了程序4G内存,当程序读或者写这段内存的时候,操作系统才会把使用的内存映射到物理内存上
物理内存和内存条之间还有一层映射
寄存器数量和容量有限,为了存储大量数据,所以我们需要内存
这里的内存其实是虚拟的,并不是真的给了程序4G内存,当程序读或者写这段内存的时候,操作系统才会把使用的内存映射到物理内存上
物理内存和内存条之间还有一层映射
EFL是32位寄存器
其中的每一位,含义都是不同的
0x00000246 16进制
0000 0000 0000 0000 0000 0010 0100 0110 二进制
第十位(从下标开始算 从右往左):DF位
DF位为``的时候: MOVS 执行完毕之后 ESI和EDI的值会增加
DF位位1的时候: MOVS 执行完毕之后 ESI和EDI的值会减少
含义:前者被后者赋值
exp:
MOV EAX,0xFFFFFFFF
此时 EAX = 0xFFFFFFFF
指令格式:
r – 通用寄存器
m – 内存
imm – 立即数
r8 – 8位通用寄存器
m8 – 8位内存
imm8 – 8位立即数
计算机在三个地方可以存数据
所谓寄存器,就是cpu中硬盘存储数据的地方
寄存器大小取决于cpu的位数
比如32位 那么cpu所提供的容器有三种 8位 16位 32位
如果64位 那么cpu所提供的容器有四种 8位 16位 32位 64位
在Winform程序中有时候调试会通过Console.Write()方式输出一些信息,这些信息是在Visual Studio的输出窗口显示。
| |
| |
| |
第二行为启动服务。
第三行为设置服务为自动运行。
最近有个奇葩需求:要把又拍云所有的图片全都下载下来 大约10T 3亿张左右
联系又拍云 能否邮寄硬盘直接拷贝,答曰不行。。但是给了个下载的python脚本
download_file_with_iter.py
我怀着感激的心情下载下来,结果一秒不到3张。。实在是慢,于是乎打算自己写一个
最近读了一篇有关arp欺骗和中间人攻击的文章,于是乎就想着自己实现一下,顺便验证下微信在回话劫持后的安全性。
DDoS攻击是常见的攻击方式,每小时大约发生28次。http://www.digitalattackmap.com提供在世界范围内的DDoS实时攻击分布图:
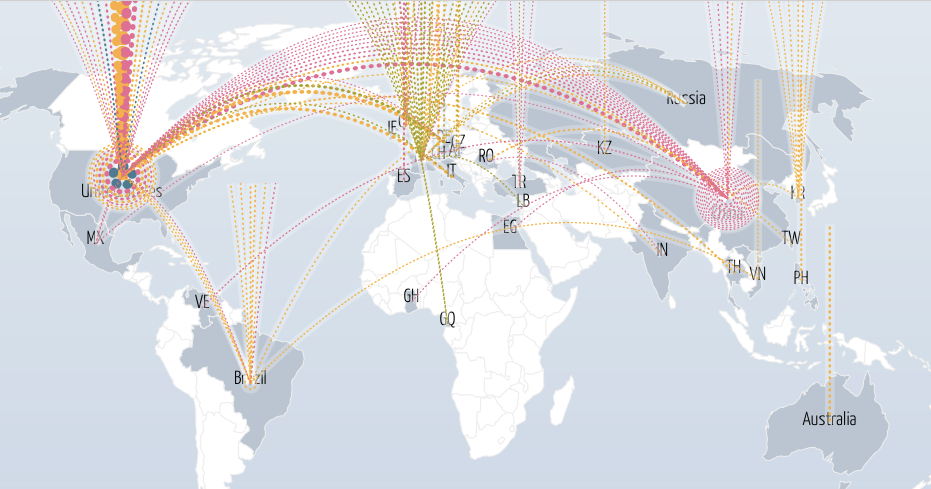
从DDoS攻击的地图上就可以看出国际形势;例如,到9月18号可以看到日本-中国的攻击;川普宣布建墙之后,可以看到墨西哥-美国的攻击。
nmap-Network Mapper,是著名的网络扫描和嗅探工具包。他同样支持Windows和OS X。
Kali Linux默认并没有安装SSH服务,为了实现远程登录Kali Linux,我们需要安装SSH服务。
HTTrack可以克隆指定网站-把整个网站下载到本地。
可以用在离线浏览上,也可以用来收集信息(甚至有网站使用隐藏的密码文件)。
你要做坏事时,最先应该想到匿名。扫描网站/主机,或利用漏洞;甚至在大天朝发帖都有风险,为了防止半夜鬼敲门,我们可以使用tor实现匿名。
sqlmap是开源的SQL注入自动攻击工具,它可以自动的探测SQL注入点并且进一步控制网站的数据库。
Metasploit提供了很多辅助的模块,非常实用。今天介绍一个叫search_email_collector的模块,它的功能是查找搜索引擎(google、bing、yahoo),收集和某个域名有关的邮箱地址。
Lynis是Linux平台上的一款安全漏洞扫描工具。它可以扫描系统的安全漏洞、收集系统信息、安装的软件信息、配置问题、没有设置密码的用户和防火墙等等。
Metasploit可以在Linux、Windows和Mac OS X系统上运行。我假设你已安装了Metasploit,或者你使用的系统是Kali Linux。它有命令行接口也有GUI接口。
我使用Kali Linux的IP地址是192.168.0.112;在同一局域网内有一台运行Windows XP(192.168.0.108)的测试电脑。
文本演示怎么使用Kali Linux入侵Android手机。
Kali Linux IP地址:192.168.0.112;接收连接的端口:443。
ettercap是执行ARP欺骗嗅探的工具,通常用它来施行中间人攻击。
我还介绍过另一个arp欺骗工具-arpspoof
我使用的是Kali Linux 2.0;在开始使用ettercap之前,先配置一下: